
🚀 One of SDTools’ specialties is to provide ad hoc solutions in the vibration domain. When an R&D project is successful, clear and efficient simulation procedures have been devised, and documented in the output.
🤝 The ability to reproduce the process is often required by our customers, which raises the question of deployment and optimization of our MATLAB based solutions into production within the customers’ framework configuration, that may not include MATLAB.
💡 Throughout the years we encountered many use cases for which we continuously improved our solutions to fit all needs, to cover GUI integration, Runtime deployment, remote computing, external solver handling, and context-based optimization.
GUI and Runtime: process integration into a standalone application fit for production
Once a simulation procedure is stabilized, its integration in a production process requires clear input and output definition, so that scripting, console prompts, or manual tweaks shall not be necessary. This is a fundamental step for accessibility to a wider audience in project contexts.
Graphical User Interface (GUI) integration is critical to accessibility nowadays and works best with processes. Our custom applications can thus be packaged this way, based on our GUI development framework. While the layout remains simple, a clear distinction is made between the graphical layer and the application core and data to enable painless further evolution, and for our concern, to optimize synergies and maintainability of all layers.
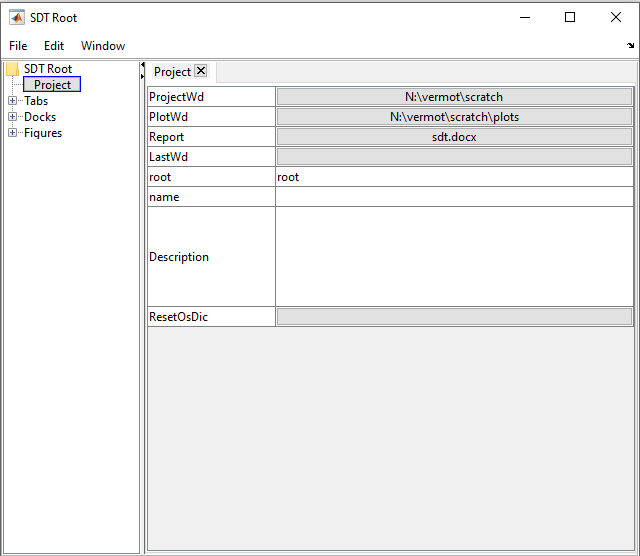
Besides purely customer driven application interfaces, SDT features its own set of interfaced procedures, for which specific actions can be altered in the custom layer. Our project tab illustrated below allows setting working directories and storing project context. You can see a specific plots directory is given, and the report entry providing a filename that our automatic reporting and capture insertion strategies will fill. You can for example check our post about automatic reporting to get further insights: https://www.sdtools.com/automatic-reporting/
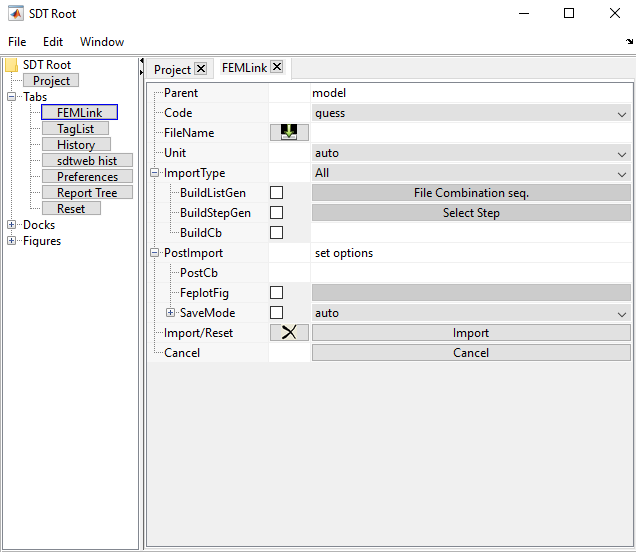
Customization is usual for our FEMLink tab, that handles model import from external codes. Many ways of constructing a working model, possibly combining input and results from other solvers, are possible. E.g. squeal simulation builds require a few additional commands and interactions with SDT-nlsim that can be bundled in the interface (prefilling, and/or alternative callbacks).
We will detail in a future post how processes can now be integrated for customized applications, stay tuned!
For such integration, since MATLAB console and editors can become optional, deployment is compatible with the fact that our customers may not already have access to MATLAB in their environment. Runtime compilation is here the solution. This enables the deployment of GUI based standalone applications, with a self-contained executable file and the free MCR program, on Windows® or Linux platforms. SDTools develops its own layer of Runtime compilation tools to integrate all external necessary features and control execution. A batch mode can also be set up to integrate advanced automated multi-software processes!
Remote computing: job handling across multi server, platform, and solver frameworks
Handling large finite element models requires significant amount of computing power. Although we mostly work on local powerstations for our consulting projects, it is rarely the case in industry or in academic labs. It means that intensive computation phases have to be performed remotely on a server, while results can be loaded on a laptop. The same problematic happens when an external solver has to be called, e.g. we sometimes rely on customers’ original setup for static preload.
SDT-sdtjob is our job management module that provides solutions to remote computing. For a given configuration, considering that local and remote platforms can be different (users typically work on Windows, but servers on Linux) the following steps have to be performed:
- Job preparation.
- gathering data related to the job files,
- local and remote directory preparation,
- input/output file list generation,
- solver options preparation,
- generation of a batch or shell file encapsulating an in-line call to the solver.
- Input file transfer. Undertaking shell or batch commands to transfer files from the local working directory to the remote one. The command is highly customizable depending on the available framework.
- Remote solver call, based on the transmitted files, and on inline command information.
- Job monitoring. To maintain continuity and coherence in the simulation process one has to ensure that the job is terminated correctly and wait or do other actions in the meantime. This process can thus be done either
- in the main process in a wait loop,
- or in an asynchronous manner on demand,
- or when the results are required to be available.
This feature is also highly customizable. It can be run remotely or locally, based on file existence or keywords in report log files. A timeout option also exists as it is not uncommon for a remote job failure not to provide exploitable information!
- Output file transfer. Similar to the input file transfer.
As one may need several server configurations, local or not, or with different resources requirements on the same server framework, it is possible to store as many configurations as needed. Our JobHost interface allows interactive definitions, but a CSV format is also possible for exploitation. The format is kept flexible enough to add custom fields when required.

SDT JobHost base tab for remote server definition
Such capability also enables job distribution strategies to be handled!
Distributed computing and parallelization matters, harnessing powerful frameworks
When dealing with large studies, large models and/or Design of Experiments (DoE), one has to devise a strategy to optimize computation time depending on the available framework. When computation servers are available many possibilities occur with typically a fair amount of RAM and plenty of cores to play with.
With the help of cloud computing, as for example Amazon Web Services, it becomes common to encounter systems with hundreds of cores and hundreds of GB of RAM. Parallelization is the obvious keyword to benefit from current architectures, but it can be implemented at different levels, keeping in mind core balance, RAM footprint and idle time.
At low level parallelization is implemented in direct operations in a process, like matrix products or factorization. This is implemented in SDT, first through MATLAB capabilities including page* functionalities, then in our own MEX files that we use for intensive operations. We use MKL libraries for such purposes, for example the PARDISO matrix inversion solver. The number of CPUs has to be controlled under the maximum to avoid system slowdown. For our usual applications, speedup passed ten to twenty cores gets asymptotical, due to memory access (load/save times and RAM to CPU transfers), and a certain level of synchronization need (e.g. in mode computation iteration the new shapes have to be orthonormalized to every previous one).
At a much higher level, DoE handling is an obvious parallelization opportunity. Each design point is typically set on a similar baseline thus requiring similar resources and computation times and can be computed independently. This implementation requires a job manager to dispatch and monitor batched jobs accordingly to accessible servers in optimized volumes. Our sdtjob module provides such implementation in its study command suite. Job runs can exploit the remote computing functionalities presented earlier, so that external solvers or compiled Runtime processes can also be run (no volume or token limitation there!). It can work locally or remotely in two different modes, as
- a single master procedure dispatching a list of jobs monitoring their completion.
- an external server launching jobs as they appear in the working directory.
For each batch, launch and run timeouts can be defined, with specific output status files for monitoring and statistics.
For even more refined needs, jobs can be split into steps with asynchronized handling in our fe_range loop functionality (https://www.sdtools.com/help/base/fe_range.html#Loop) that typically prepares jobs to be run. One can then optimize pre/solve/post steps separately depending on their intensity.
Optimization in constrained environments
Dealing with large models and big DoE is accessible with powerstations and servers, but sometimes one has to resort to a local computer to display results or run a specific computation. When all the data cannot fit in the RAM, alternative strategies are required to maintain usability using the options detailed in our documentation https://www.sdtools.com/help/base/simul.html#fesk
Out-of-core procedures involve unloading the RAM by writing live data on disc, working variables then become pointer objects whose methods overload usual commands. Matrix operations can then be buffered, and large results or by-products can also be written to disc directly. SDT exploits MATLAB HDF5 file format (v7.3), or the older (v6) format to remain compatible with standard files, but uses its own functionalities optimized for our usual applications. Of course, pointers can be directly generated from files when accessing results. One can set the OutOfCoreBufferSize preference to optimize buffer size depending on the framework.
As writing to disc significantly slows down the processes, a lighter RAM saving strategy is also implemented on SDT. For these intermediate cases, the assembled model can be stored in RAM, but most operations would tend to saturate it. This case corresponds for example to few million DOF models with 30 to 100 GB RAM. For these kinds of models, computing 100 modes or playing with multi-model reduction does not directly pass in-core due to by-products and memory duplication induced by the operations. In-core blockwise operations can here be implemented to limit the RAM overload by memory duplication and therefore pass procedures with a limited slowdown (typically 2 to 4). We’ve had great results with this strategy. These preferences are named EigOOC, BlasBufSize and MklservBufSize.
Another memory reduction strategy focuses on storage and display optimization. When the full system modes are not required for other procedures, one can only store restitution data for display. This is a common way of saving storage data by only keeping information at selected nodes. Our latest display strategy exploits plane cuts to generate very small datasets while maximizing information, getting from the Giga to the Mega scale in terms of data storage and fluidity for display. We have already showcased this feature in a previous post https://www.sdtools.com/reduced-model-animation-on-reduced-mesh-through-cuts-slices/

Display strategy to optimize data storage and fluidity. From full mesh (1GB data to display) to light plane cuts (1.2MB data to display)